Filter layer rebased #2054
Filter layer rebased #2054
Conversation
BTW, I have asked guys who wrote this paper about their plans releasing their caffe code. The answer was no, until paper got`s accepted. |
|
Another one with some possible relation to this PR: Error-Driven Incremental Learning in Deep Convolutional Neural Network for Large-Scale Image Classification |
This still doesn't make sense to me. If your labels are not a function of the network weights, Caffe will already figure out that they do not need backpropagation. This is how all of our current loss layers work -- Caffe figures out that the labels are a net "input" (i.e., unaffected by the weights) and hence we have Maybe there is a use case for adding a proto field |
|
@jeffdonahue |
|
Thanks for the example @ducha-aiki -- it does seem useful to have a way of indicating that backprop should be truncated for particular bottoms of particular layers, or more generally a way to scale the bottom diff by a particular scale factor other than 1 (e.g., 0 if you want to truncate). It would also be a convenient way to freeze all layers of the net up to layer K without having to set I am happy to review a separate PR which does the following:
For this PR, I can review it again when the |
|
thank you for your example @ducha-aiki. |
|
I think that @jeffdonahue told that he want only review a separte PR with skip_propagate_down and not to write himself one. |
|
@longjon Do you remember our discussion on this? |
You are misunderstanding -- Caffe will not think your labels need backpropagation if they aren't the output (direct or indirect) of a layer with weights. For example, if you have a data layer that directly produces the FilterLayer labels, FilterLayer will work fine without any It is important that if you put a layer in a network and it needs to be able to backpropagate (i.e., the loss is influenced by the weights via the layer), but can't, that Caffe will correctly complain and fail to train in this case. However, I agree that sometimes it could be desirable to train the net in spite of that, as in @ducha-aiki's example and other cases, but such an option (1) shouldn't be called So yes, I will wait to review this PR once the |
|
I agree with point 2, maybe a more general param could be useful in cases beyond this filter layer and to avoid redundancy the In this case the By the way me and @bhack are thinking about implementing this
|
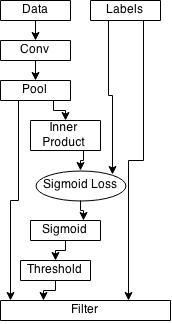
|
Meanwhile you could have two filter layers, one that filter the Sergio 2015-03-09 12:12 GMT-07:00 Manuele notifications@github.com:
|
|
@sguada Is your comment the same of #1482 (comment) and that @mtamburrano replied with #1482 (comment)? Is there something different? |
|
@bhack yeah my comment is the same, for the label part of filter one doesn't need to back-propagate while for the data part of filter it will back-propagate as needed. I think you should try to implement the simplest filter layer possible and address problems in future PRs, otherwise this will never reach a merge-able point. |
|
@mtamburrano right, I understand the use case, and your example makes sense. Note that in your example you would add
It is probably easier/better to weave in the logic where Net is already setting
How about the example you drew? You can turn it into a prototxt string, and add a new test case to |
I'd like to use my example for tests, but if I have to open a separate PR for the new parameter, I can't use this unmerged layer for running tests. Or rather, I can write the code, but the travis build will not succeed... |
|
The test doesn't need to use a |
|
@jeffdonahue the new PR is live at #2095 |
|
|
|
@jeffdonahue I see that somebody is tagging PR as "ready for review". Can you tag also this one? |
|
@jeffdonahue Can you pass here? |
|
@mtamburrano Seems that It needs a rebase again. |
|
@jeffdonahue We want to program our activity to reserve a little bit of time for this. Do you need other changes or is it mergeable? |
|
@jeffdonahue Can we squash also this? Do you think is it ready? |
| // Message that stores parameters used by FilterLayer | ||
| message FilterParameter { | ||
| // specify which blobs need to be backpropagated and which not | ||
| repeated uint32 need_back_prop = 1 [packed = true]; |
There was a problem hiding this comment.
This shouldn't be needed after #2095 right?
|
removed @jeffdonahue I would like to remember that this PR now works, but to correctly treats with zero-sized batches, it still needs #2053 (although seems it is not only |
|
@jeffdonahue Can we try to merge this before CVPR? We can allocate a little bit more time if you need some other little fixes. |
|
rebased on master again. |
|
@jeffdonahue (@sguada amarcord) Since 18 Nov 2014 in #1448. This PR is becoming barrel aged edition! |
|
|
||
| template <typename Dtype> | ||
| void FilterLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top, | ||
| const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom) { |
There was a problem hiding this comment.
This should have something like CHECK(!propagate_down[bottom.size() - 1]) << this->type() << "Layer cannot backpropagate to filter index inputs" (like SoftmaxWithLossLayer for labels, etc.). Same comment in Backward_gpu. (This will make the gradient check fail, but you give it bottom ID 0 as an additional argument to only check that input.)
|
Okay, please add a check as I commented above, squash, and I'll merge. |
e32982b
to
c24d184
Compare
|
Check added, test updated and squashed all commits. I would to point up again that without #2053, if a |
|
seems like Travis fails first 2 builds because not every tests pass. |
|
Not sure what happened but your diff is now huge. Did you rebase on the latest master? |
|
@mtamburrano The problem seems that now it is rebased on mtamburrano@596add7 but caffe master is at b12c171 |
c24d184
to
596add7
Compare
b28e03d
to
ae4a5b1
Compare
d234166
to
8a2b4e8
Compare
|
I think I did something wrong when I squashed commits, everything should be fine now. |
|
@jeffdonahue Seems rebased correctly now. Can you pass here? |
|
Thanks @mtamburrano! Merged @ 21b6bf8. I fixed a bug in the GPU backward implementation (gradient test was segfaulting) and did some minor comment/style cleanup @ 0ccf336. |
This is the new PR based on old #1482 which was not mergeable anymore
The blobs are now treated as N dimensional entities.
To correctly deal with 0 sized batches (it could be happen when all the data is filtered) this PR needs #2053
To allow discriminating backprop this layer needs #2052
Possible use case:
HD-CNN: Hierarchical Deep Convolutional Neural Network for Image Classification
Old description: